Joint联合抽取方法介绍¶
学习目标¶
- 理解Joint方法的原理
- 掌握Casrel模型的原理及架构组成
- 掌握Casrel模型的代码实现
- 掌握Joint方法的优缺点
1 Joint方法的原理¶
joint联合抽取方法是通过修改标注方法和模型结构直接输出文本中包含的(ei,rk,ej)三元组. Joint联合抽取方法又分为: "参数共享的联合模型" 和 "联合解码的联合模型":
- 参数共享的联合模型:
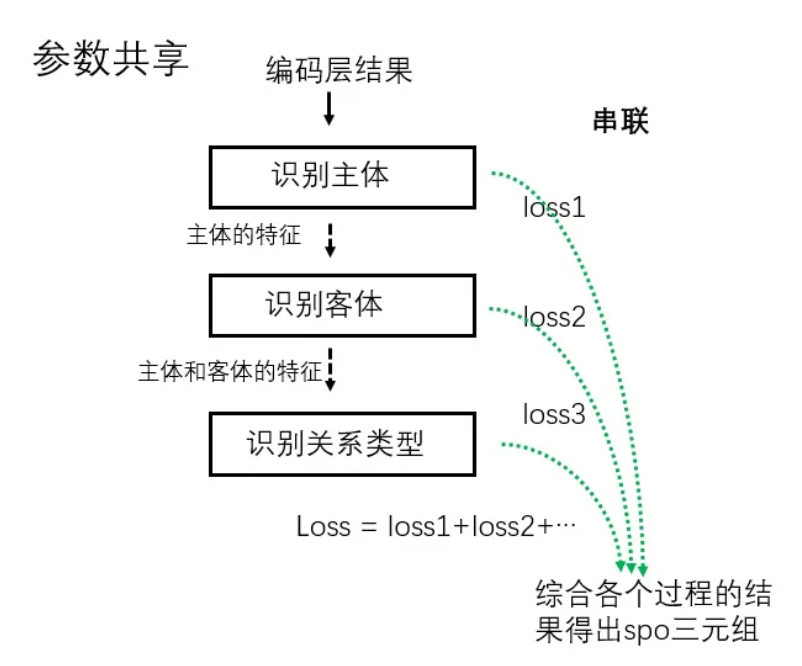
- 主体、客体和关系的抽取不是同步的 (一般情况,但是也可以其中两个任务一起进行) ,各个过程都可以得到一个loss值,整个模型的loss是各过程loss值之和.
- 联合解码的联合模型:
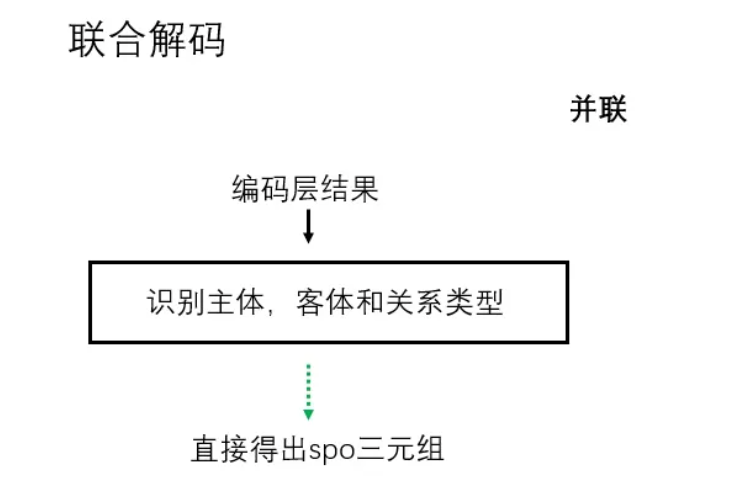
- 主体、客体和关系的抽取是同步的,通过一个模型直接得到SPO三元组. 如: 采用序列标注形式实现模型训练,如果有N种关系,对于每种关系,将其与BIOS以及主实体和客实体的序号 (1,2) 组合起来进行关系抽取,并根据最后的标注结果进行解码,一共涉及 2×3×N+1个标签 (其中1代表不属于任何一种关系) .
2 Casrel算法思想¶
- Casrel是2020 ACL 上的实体关系抽取的一篇论文,该论文的主要解决的问题为关系三元组重叠问题.
- CasRel 本质上是基于参数共享的联合实体关系抽取方法.
3 Casrel模型架构¶
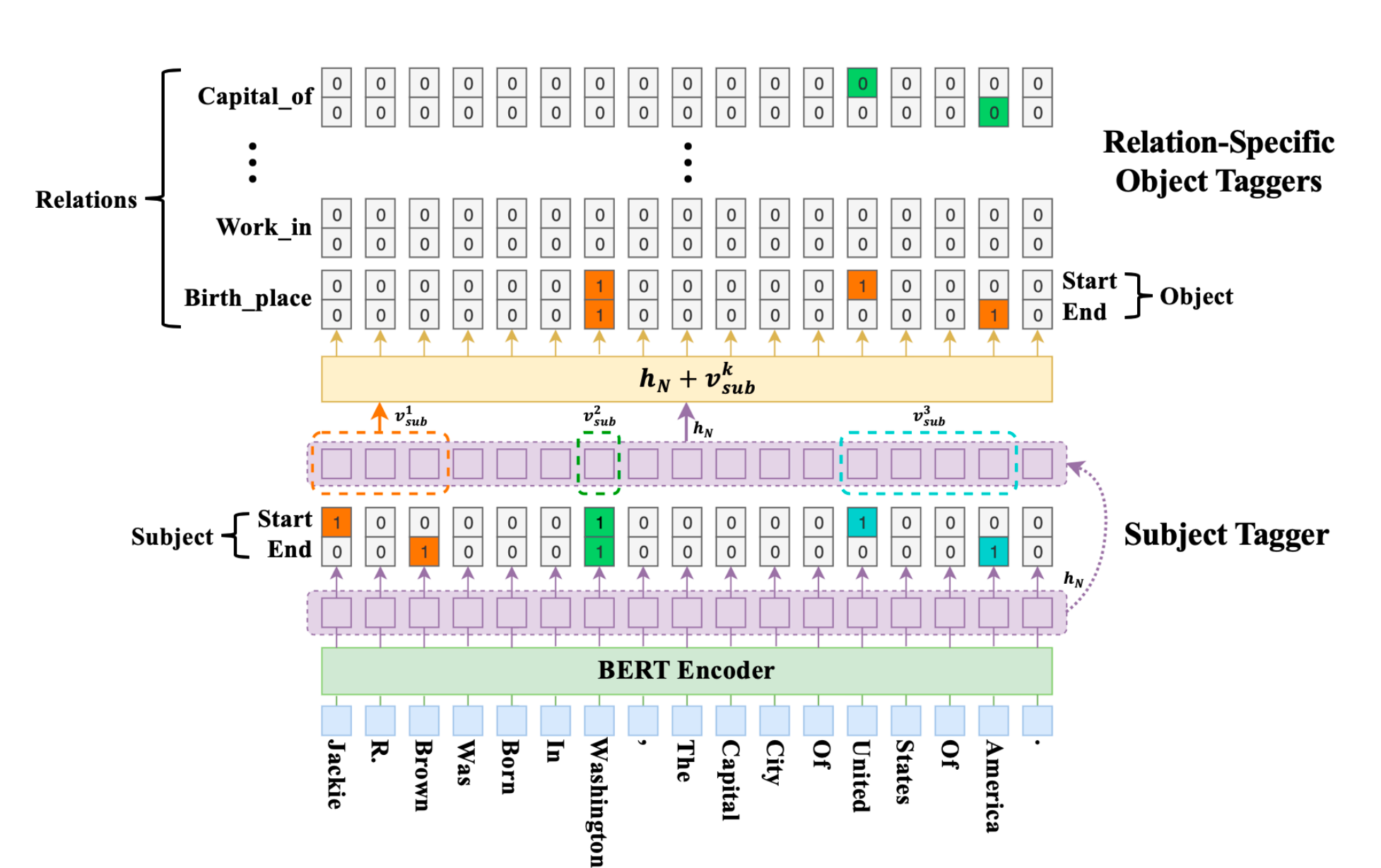
- CASREL框架抽取三元组(subject, relation, object)主要包含两个步骤,三个部分
- 两个步骤:
- 第一步要识别出句子中的 subject .
- 第二部要根据识别出的 subject, 识别出所有有可能的 relation 以及对应的 object.
- 三个部分:
- 编码器部分: 可以替换为不同的编码框架,主要对句子中的词进行编码,论文最终以BERT为主,效果不错.
- 解码器—-头实体识别部分:目的是识别出句子中的 subject.
- 解码器—-关系与尾实体联合识别部分:根据 subject,寻找可能的 relation 和 object.
3.1 模型细节¶
头实体识别部分¶
- CasRel的头实体识别层直接对编码层的结果进行解码,去识别所有可能的头实体. 这里CasRel是识别头实体span,也就是start和end位置,所以它采用的是二分类.

- 因此,模型本身很简单:
- 首先,利用一个线性层➕一个sigmoid激活函数判断每个token是不是头实体的开始token或结束token
- 然后,利用最近匹配原则将识别到的start和end配对获得候选头实体集合.
关系、尾实体联合识别部分¶
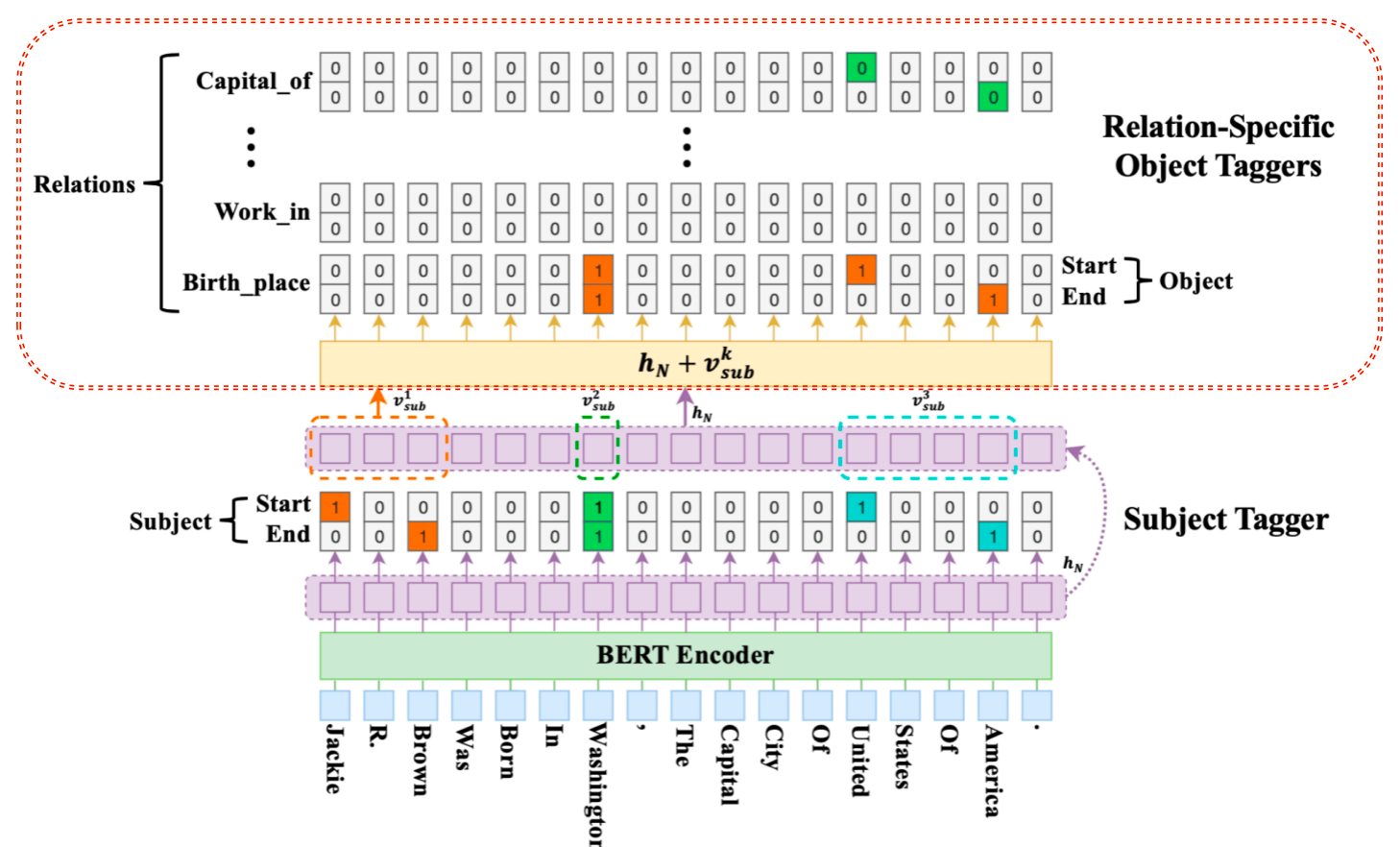
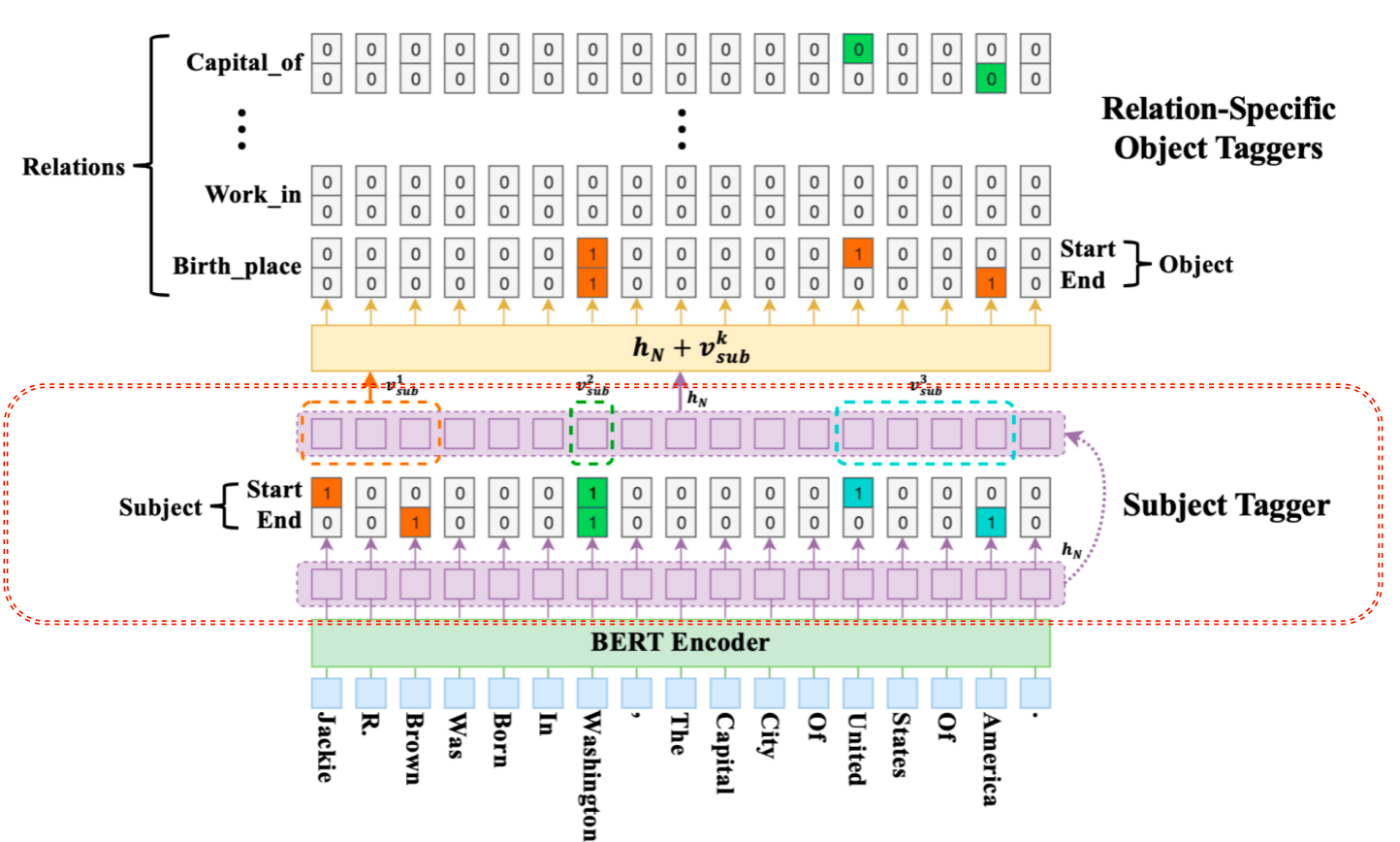
- 识别头实体后就要进行关系和尾实体的联合识别了. 这里每一层尾实体识别层的结构其实与头实体识别层是一样的,不同主要在于输入:
- 解码的时候比subject不仅仅考虑了BERT编码的隐层向量, 还考虑了识别出来的subject特征,即下图.
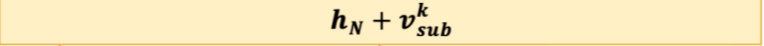
- vsub 代表 subject 特征向量,若存在多个词,将其取向量平均,hn代表 BERT 编码向量.
- 对于识别出来的每一个subject, 对应的每一种关系会解码出其 object 的 start 和 end 索引位置,与 Subject 类似,公式如下:
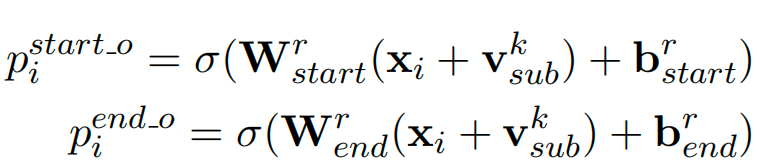
模型结果:¶
- 以图中的例子解析下模型最终的预测结果,图中的第一个 subject 的过程,即 Jackie R. Brown,对于这个subject,在关系 Birth_place 中识别出了两个 object,即 Washington 和 United States Of America,而在其他的关系中未曾识别出相应的 object. 当对 Washington 这个 subject 解码时,仅仅在 Capital_of 的关系中识别出对应的 object: United States Of America.
3.2 Casrel模型解决的问题¶
- 由上述模型结果得出结论:Casrel模型可以解决最开始提到关系抽取中的 SEO 和 EPO 的重叠问题. 这也是我们本次项目研究问题的重点,解决文本中多元关系问题.
4 项目代码架构图¶

5 数据预处理¶
- 本项目中对数据部分的预处理步骤如下:
- 第一步: 查看项目数据集
- 第二步: 编写Config类项目文件配置代码
- 第三步: 编写数据处理相关函数
- 第四步: 构建DataSet类与dataloader函数
第一步: 查看项目数据集¶
- 本次项目数据来源为公开的千言数据集https://www.luge.ai/#/,使用开源数据的好处,我们无需标注直接使用即可,本次项目的主要目的, 需要大家掌握实现关系抽取的思想.
- 注意:实际工作中,数据一般需要人工手动标注.
- 项目数据的路径为:/home/ec2-user/Casrel_RE/relationship_extract/data
- 项目的数据集包括6个json文件(其中predict_spo.json是模型预测结果,rel_type.json是带有实体类型的关系文件), 我们这里只先针对train.json、dev.json、test.json、relation.json进行介绍:
- 关系类型文件: /home/ec2-user/Casrel_RE/relationship_extract/data/relation.json
{
"0": "出品公司",
"1": "国籍",
"2": "出生地",
"3": "民族",
"4": "出生日期",
"5": "毕业院校",
"6": "歌手",
"7": "所属专辑",
"8": "作词",
"9": "作曲",
"10": "连载网站",
"11": "作者",
"12": "出版社",
"13": "主演",
"14": "导演",
"15": "编剧",
"16": "上映时间",
"17": "成立日期"
}
- rel.json中包含18个类别标签, json文件可以看作是一个字典,key对应关系的id,value对应关系类型.
- 训练数据集: /home/ec2-user/Casrel_RE/relationship_extract/data/train.json
{"text": "笔 名:木斧原 名:杨莆曾 用 名:穆新文、牧羊、寒白、洋漾出生日期:1931—职 业:作家、诗人性 别: 男民 族: 回族政治面貌:中共党员 祖 籍:固原县出 生 地:成都", "spo_list": [{"predicate": "民族", "object_type": "文本", "subject_type": "人物", "object": "回族", "subject": "木斧"}, {"predicate": "出生日期", "object_type": "日期", "subject_type": "人物", "object": "1931", "subject": "木斧"}, {"predicate": "出生地", "object_type": "地点", "subject_type": "人物", "object": "成都", "subject": "木斧"}]}
{"text": "《今晚会在哪里醒来》是黄家强的一首粤语歌曲,由何启弘作词,黄家强作曲编曲并演唱,收录于2007年08月01日发行的专辑《她他》中", "spo_list": [{"predicate": "作曲", "object_type": "人物", "subject_type": "歌曲", "object": "黄家强", "subject": "今晚会在哪里醒来"}, {"predicate": "所属专辑", "object_type": "音乐专辑", "subject_type": "歌曲", "object": "她他", "subject": "今晚会在哪里醒来"}, {"predicate": "歌手", "object_type": "人物", "subject_type": "歌曲", "object": "黄家强", "subject": "今晚会在哪里醒来"}, {"predicate": "作词", "object_type": "人物", "subject_type": "歌曲", "object": "何启弘", "subject": "今晚会在哪里醒来"}]}
{"text": "2003年12月26日,公司2003年第四次临时股东大会批准,公司名称变更为“华夏建通科技开发股份有限公司”,并于2004年6月3日取得河北省工商行政管理局换发的《企业法人营业执照》,法定代表人:何强", "spo_list": [{"predicate": "成立日期", "object_type": "日期", "subject_type": "企业", "object": "2004年6月3日", "subject": "华夏建通科技开发股份有限公司"}]}
{"text": "潘惟南,陕西大荔县溢渡村人", "spo_list": [{"predicate": "出生地", "object_type": "地点", "subject_type": "人物", "object": "陕西大荔", "subject": "潘惟南"}]}
train.json中包含55433行样本, 每行为一个字典样式, 第一个key为"text", 对应的value为待抽取关系的中文文本, 第二个key为"spo_list", 对应的value为句子中真实的spo关系三元组列表 (列表中含有多个spo三元组)
以spo_list的其中一个元素为例:元素格式为字典,其中"predictate"代表为关系类型; "object_type"代表尾实体的类型; "subject_type"代表主实体的类型; "object"代表尾实体; "subject" 代表主实体.
- 验证数据集: /home/ec2-user/Casrel_RE/relationship_extract/data/dev.json
{"text": "蔡志坚在南京艺术学院求学时受过系统、正规的艺术教育和专业训练,深得刘海粟、罗叔子、陈之佛、谢海燕、陈大羽等著名中国画大师的指授,基本功扎实,加上他坚持从生活中汲取创作源泉,用心捕捉生活中最美最感人的瞬间形象,因而他的作品,不论是山水、花鸟、飞禽、走兽,无不充满了生命的灵气,寄托着画家的情怀,颇得自然之真趣", "spo_list": [{"predicate": "毕业院校", "object_type": "学校", "subject_type": "人物", "object": "南京艺术学院", "subject": "蔡志坚"}]}
{"text": "人物简介1974年1月出生,副教授 ,学历硕士 赵明,出生于1974年1月,毕业于武汉音乐学院管弦系,是洛阳师范学院音乐学院教授", "spo_list": [{"predicate": "毕业院校", "object_type": "学校", "subject_type": "人物", "object": "武汉音乐学院", "subject": "赵明"}]}
{"text": "韩国电视剧《一枝梅归来》(又名《美贼一枝梅传》),改编自韩国漫画作家高羽荣的漫画,由黄仁雷执导,丁一宇和尹珍序等联袂出演", "spo_list": [{"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "丁一宇", "subject": "一枝梅归来"}, {"predicate": "导演", "object_type": "人物", "subject_type": "影视作品", "object": "黄仁雷", "subject": "一枝梅归来"}]}
{"text": "《结了》是一首由郝云演唱的歌曲,由郝云填词,曲改编自华盛顿广场,收录于专辑《突然想到理想这个词》中", "spo_list": [{"predicate": "作曲", "object_type": "人物", "subject_type": "歌曲", "object": "改编自华盛顿广场", "subject": "结了"}]}
dev.json中包含11191行样本, 每行为一个字典样式, 第一个key为"text", 对应的value为待抽取关系的中文文本, 第二个key为"spo_list", 对应的value为句子中真实的spo关系三元组列表 (列表中含有多个spo三元组)
以spo_list的其中一个元素为例:元素格式为字典,其中"predictate"代表为关系类型; "object_type"代表尾实体的类型; "subject_type"代表主实体的类型; "object"代表尾实体; "subject" 代表主实体.
- 测试数据集: /home/ec2-user/Casrel_RE/relationship_extract/data/test.json
{"text": "1997年,李柏光从北京大学法律系博士毕业", "spo_list": [{"predicate": "毕业院校", "object_type": "学校", "subject_type": "人物", "object": "北京大学", "subject": "李柏光"}]}
{"text": "当《三生三世》4位女星换上现代装:第四,安悦溪在《三生三世十里桃花》中饰演少辛,安悦溪穿上现代装十分亮眼,气质清新脱俗", "spo_list": [{"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "安悦溪", "subject": "三生三世十里桃花"}]}
{"text": "山东海益宝水产股份有限公司成立于2002年,坐落在风景秀丽的中国胶东半岛,是一家以高科技海产品的育苗、养殖、研发、加工、销售为一体的综合性新型产业化水产企业,拥有标准化深海围堰基地,是山东省水产养殖行业的龙头企业之一,同时也是国内日本红参与胶东参杂交参种产业化生产基地", "spo_list": [{"predicate": "成立日期", "object_type": "日期", "subject_type": "机构", "object": "2002年", "subject": "山东海益宝水产股份有限公司"}]}
{"text": "《骑士之爱与游吟诗人》是上海社会科学院出版社2012年出版的图书,作者是英国的 菲奥娜·斯沃比", "spo_list": [{"predicate": "出版社", "object_type": "出版社", "subject_type": "图书作品", "object": "上海社会科学院出版社", "subject": "骑士之爱与游吟诗人"}, {"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "菲奥娜·斯沃比", "subject": "骑士之爱与游吟诗人"}]}
test.json中包含13417行样本, 每行为一个字典样式, 第一个key为"text", 对应的value为待抽取关系的中文文本, 第二个key为"spo_list", 对应的value为句子中真实的spo关系三元组列表 (列表中含有多个spo三元组)
以spo_list的其中一个元素为例:元素格式为字典,其中"predictate"代表为关系类型; "object_type"代表尾实体的类型; "subject_type"代表主实体的类型; "object"代表尾实体; "subject" 代表主实体.
第二步:编写Config类项目文件配置代码¶
- Config类文件路径为: /home/ec2-user/Casrel_RE/relationship_extract/codes/config.py
- config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
# 导入必备的工具包
import torch
# 导入Vocabulary,目的:用于构建, 存储和使用 `str` 到 `int` 的一一映射
from fastNLP import Vocabulary
from transformers import BertTokenizer, AdamW
import json
# 构建配置文件Config类
class Config(object):
def __init__(self):
# 设置是否使用GPU来进行模型训练
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.bert_path = "预训练模型的绝对路径"
self.num_rel = 18 # 关系的种类数
self.batch_size = 8
self.train_data_path = "训练数据集的绝对路径"
self.dev_data_path = "验证数据集的绝对路径"
self.test_data_path = "测试数据集的绝对路径"
self.rel_dict_path = "关系数据文件的绝对路径"
id2rel = json.load(open(self.rel_dict_path, encoding='utf8'))
self.rel_vocab = Vocabulary(padding=None, unknown=None)
# vocab更新自己的字典,输入为list列表
self.rel_vocab.add_word_lst(list(id2rel.values()))
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.learning_rate = 1e-5
self.bert_dim = 768
self.epochs = 10
第三步: 编写数据处理相关函数¶
- 函数代码路径: /home/ec2-user/Casrel_RE/relationship_extract/codes/utils/process.py
- 首选导入必备的工具包
# coding:utf-8
from codes.config import *
import torch
from random import choice
from collections import defaultdict
conf = Config()
- 构建第一个数据处理相关函数find_head_idx, 位于process.py中的独立函数.
def find_head_idx(source, target):
# # 获取实体的开始索引位置
target_len = len(target)
for i in range(len(source)):
if source[i: i + target_len] == target:
return i
return -1
- 构建第二个数据处理相关函数create_label, 位于process.py中的独立函数.
def create_label(inner_triples, inner_input_ids, seq_len):
# 获取每个样本的:主实体长度、主实体开始和结束位置张量表示、客实体以及对应关系实现张量表示
inner_sub_heads, inner_sub_tails = torch.zeros(seq_len), torch.zeros(seq_len)
inner_obj_heads = torch.zeros((seq_len, conf.num_rel))
inner_obj_tails = torch.zeros((seq_len, conf.num_rel))
inner_sub_head2tail = torch.zeros(seq_len) # 随机抽取一个实体,从开头一个词到末尾词的索引
# 因为数据预处理代码还待优化,会有不存在关系三元组的情况,
# 初始化一个主词的长度为1,即没有主词默认主词长度为1,
# 防止零除报错,初始化任何非零数字都可以,没有主词分子是全零矩阵
inner_sub_len = torch.tensor([1], dtype=torch.float)
# 主词到谓词的映射
s2ro_map = defaultdict(list)
# print(s2ro_map)
for inner_triple in inner_triples:
# print(inner_triple)
inner_triple = (
conf.tokenizer(inner_triple['subject'], add_special_tokens=False)['input_ids'],
conf.rel_vocab.to_index(inner_triple['predicate']),
conf.tokenizer(inner_triple['object'], add_special_tokens=False)['input_ids']
)
sub_head_idx = find_head_idx(inner_input_ids, inner_triple[0])
obj_head_idx = find_head_idx(inner_input_ids, inner_triple[2])
if sub_head_idx != -1 and obj_head_idx != -1:
sub = (sub_head_idx, sub_head_idx + len(inner_triple[0]) - 1)
# s2ro_map保存主语到谓语的映射
s2ro_map[sub].append(
(obj_head_idx, obj_head_idx + len(inner_triple[2]) - 1, inner_triple[1])) # {(3,5):[(7,8,0)]} 0是关系
if s2ro_map:
for s in s2ro_map:
inner_sub_heads[s[0]] = 1
inner_sub_tails[s[1]] = 1
sub_head_idx, sub_tail_idx = choice(list(s2ro_map.keys()))
inner_sub_head2tail[sub_head_idx:sub_tail_idx + 1] = 1
inner_sub_len = torch.tensor([sub_tail_idx + 1 - sub_head_idx], dtype=torch.float)
for ro in s2ro_map.get((sub_head_idx, sub_tail_idx), []):
inner_obj_heads[ro[0]][ro[2]] = 1
inner_obj_tails[ro[1]][ro[2]] = 1
return inner_sub_len, inner_sub_head2tail, inner_sub_heads, inner_sub_tails, inner_obj_heads, inner_obj_tails
- 构建第三个数据处理相关函数collate_fn, 位于process.py中的独立函数.
def collate_fn(data):
text_list = [value[0] for value in data]
triple = [value[1] for value in data]
# 按照batch中最长句子补齐
text = conf.tokenizer.batch_encode_plus(text_list,padding=True)
batch_size = len(text['input_ids'])
seq_len = len(text['input_ids'][0])
sub_heads = []
sub_tails = []
obj_heads = []
obj_tails = []
sub_len = []
sub_head2tail = []
# 循环遍历每个样本,将实体信息进行张量的转化
for batch_index in range(batch_size):
inner_input_ids = text['input_ids'][batch_index] # 单个句子变成索引后
inner_triples = triple[batch_index]
# 获取每个样本的:主实体长度、主实体开始和结束位置张量表示、客实体以及对应关系实现张量表示
results = create_label(inner_triples, inner_input_ids, seq_len)
sub_len.append(results[0])
sub_head2tail.append(results[1])
sub_heads.append(results[2])
sub_tails.append(results[3])
obj_heads.append(results[4])
obj_tails.append(results[5])
input_ids = torch.tensor(text['input_ids']).to(conf.device)
mask = torch.tensor(text['attention_mask']).to(conf.device)
# 借助torch.stack()函数沿一个新维度对输入batch_size张量序列进行连接,序列中所有张量应为相同形状;stack 函数返回的结果会新增一个维度,
sub_heads = torch.stack(sub_heads).to(conf.device)
sub_tails = torch.stack(sub_tails).to(conf.device)
sub_len = torch.stack(sub_len).to(conf.device)
sub_head2tail = torch.stack(sub_head2tail).to(conf.device)
obj_heads = torch.stack(obj_heads).to(conf.device)
obj_tails = torch.stack(obj_tails).to(conf.device)
inputs = {
'input_ids': input_ids,
'mask': mask,
'sub_head2tail': sub_head2tail,
'sub_len': sub_len
}
labels = {
'sub_heads': sub_heads,
'sub_tails': sub_tails,
'obj_heads': obj_heads,
'obj_tails': obj_tails
}
return inputs, labels
第四步:构建DataSet类以及Dataloader函数¶
- 代码路径为: /home/ec2-user/Casrel_RE/relationship_extract/codes/utils/data_loader.py
- 首先导入相应的工具包
# coding:utf-8
from torch.utils.data import DataLoader, Dataset
from utils.process import *
conf = Config()
- 构建第一个数据处理相关类MyDataset, 位于data_loader.py中的独立类.
# 自定义Dataset
class MyDataset(Dataset):
def __init__(self, data_path):
super(MyDataset, self).__init__()
self.dataset = [json.loads(line) for line in open(data_path, encoding='utf8')]
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
content = self.dataset[index]
text = content['text']
spo_list = content['spo_list']
return text, spo_list
- 构建第二个数据处理相关函数get_data, 位于data_loader.py中的独立函数.
def get_data():
# 实例化训练数据集Dataset对象
train_data = MyDataset(conf.train_data_path)
# 实例化验证数据集Dataset对象
dev_data = MyDataset(conf.dev_data_path)
# 实例化测试数据集Dataset对象
test_data = MyDataset(conf.test_data_path)
# 实例化训练数据集Dataloader对象
train_dataloader = DataLoader(dataset=train_data,
batch_size=conf.batch_size,
shuffle=True,
collate_fn=collate_fn,
drop_last=True)
# 实例化验证数据集Dataloader对象
dev_dataloader = DataLoader(dataset=dev_data,
batch_size=conf.batch_size,
shuffle=True,
collate_fn=collate_fn,
drop_last=True)
# 实例化测试数据集Dataloader对象
test_dataloader = DataLoader(dataset=test_data,
batch_size=conf.batch_size,
shuffle=True,
collate_fn=collate_fn,
drop_last=True)
return train_dataloader, dev_dataloader, test_dataloader
6 Casrel模型搭建¶
- 本项目中Casrel模型搭建的步骤如下:
- 第一步: 编写模型类的代码
- 第二步: 编写工具类函数,训练函数,验证函数,测试函数
- 第三步: 编写使用模型预测代码的实现.
第一步: 编写模型类的代码¶
- 文本编码采用的是BERT预训练模型
- 第一步: 实现CasRel类代码.
- 代码路径: /home/ec2-user/Casrel_RE/relationship_extract/codes/model/CasrelModel.py
# coding:utf-8
import torch
import torch.nn as nn
from transformers import BertModel, AdamW
from codes.config import *
class CasRel(nn.Module):
def __init__(self, conf):
super().__init__()
self.bert = BertModel.from_pretrained(conf.bert_path)
# 定义第一个线性层,来判断主实体的头部位置
self.sub_heads_linear = nn.Linear(conf.bert_dim, 1)
# 定义第二个线性层,来判断主实体的尾部位置
self.sub_tails_linear = nn.Linear(conf.bert_dim, 1)
# 定义第三个线性层,来判断客实体的头部位置以及关系类型
self.obj_heads_linear = nn.Linear(conf.bert_dim, conf.num_rel)
# 定义第四个线性层,来判断客实体的尾部位置以及关系类型
self.obj_tails_linear = nn.Linear(conf.bert_dim, conf.num_rel)
def get_encoded_text(self, token_ids, mask):
encoded_text = self.bert(token_ids, attention_mask=mask)[0]
return encoded_text
def get_subs(self, encoded_text):
pre_sub_heads = torch.sigmoid(self.sub_heads_linear(encoded_text))
pre_sub_tails = torch.sigmoid(self.sub_tails_linear(encoded_text))
return pre_sub_heads, pre_sub_tails
def get_objs_for_specific_sub(self, sub_head2tail, sub_len, encoded_text):
'''
将subject实体信息融合原始句子中:将主实体字向量实现平均,然后加在当前句子的每一个字向量上,进行计算
:param sub_head2tail:shape-->【16,1, 200】
:param sub_len:shape--->[16,1]
:param encoded_text:.shape[16,200,768]
:return:
pred_obj_heads-->shape []
pre_obj_tails-->shape []
'''
sub = torch.matmul(sub_head2tail, encoded_text)# 将主实体特征和编码后的文本进行融合
sub_len = sub_len.unsqueeze(1) # 主实体长度(扩维)
sub = sub / sub_len # 平均主实体信息
encoded_text = encoded_text + sub #将处理后的实体特征和原始编码后的文本进行融合
pred_obj_heads = torch.sigmoid(self.obj_heads_linear(encoded_text))
pre_obj_tails = torch.sigmoid(self.obj_tails_linear(encoded_text))
return pred_obj_heads, pre_obj_tails
def forward(self, input_ids, mask, sub_head2tail, sub_len):
'''
:param input_ids: shape-->[16, 200]
:param mask: shape-->[16, 200]
:param sub_head2tail: shape-->[16, 200]
:param sub_len: shape-->[16, 1]
:return:
'''
# todo: encode_text.shape--->[16,200,768]
encoded_text = self.get_encoded_text(input_ids, mask)
pred_sub_heads, pre_sub_tails = self.get_subs(encoded_text)
sub_head2tail = sub_head2tail.unsqueeze(1)
pred_obj_heads, pre_obj_tails =self.get_objs_for_specific_sub(sub_head2tail, sub_len,encoded_text)
result_dict = {'pred_sub_heads': pred_sub_heads,
'pred_sub_tails': pre_sub_tails,
'pred_obj_heads': pred_obj_heads,
'pred_obj_tails': pre_obj_tails,
'mask': mask}
return result_dict
def compute_loss(self,
pred_sub_heads, pred_sub_tails,
pred_obj_heads, pred_obj_tails,
mask,
sub_heads, sub_tails,
obj_heads, obj_tails):
'''
计算损失
:param pred_sub_heads:[16, 200, 1]
:param pred_sub_tails:[16, 200, 1]
:param pred_obj_heads:[16, 200, 18]
:param pred_obj_tails:[16, 200, 18]
:param mask: shape-->[16, 200]
:param sub_heads: shape-->[16, 200]
:param sub_tails: shape-->[16, 200]
:param obj_heads: shape-->[16, 200, 18]
:param obj_tails: shape-->[16, 200, 18]
:return:
'''
# todo:sub_heads.shape,sub_tails.shape, mask-->[16, 200]
# todo:obj_heads.shape,obj_tails.shape-->[16, 200, 18]
rel_count = obj_heads.shape[-1]
rel_mask = mask.unsqueeze(-1).repeat(1, 1, rel_count)
loss_1 = self.loss(pred_sub_heads, sub_heads, mask)
loss_2 = self.loss(pred_sub_tails, sub_tails, mask)
loss_3 = self.loss(pred_obj_heads, obj_heads, rel_mask)
loss_4 = self.loss(pred_obj_tails, obj_tails, rel_mask)
return loss_1 + loss_2 + loss_3 + loss_4
def loss(self, pred, gold, mask):
pred = pred.squeeze(-1)
los = nn.BCELoss(reduction='none')(pred, gold)
if los.shape != mask.shape:
mask = mask.unsqueeze(-1)
los = torch.sum(los * mask) / torch.sum(mask)
return los
def load_model(conf):
device = conf.device
model = CasRel(conf)
model.to(device)
# 因为本次模型借助BERT做fine_tuning, 因此需要对模型中的大部分参数进行L2正则处理防止过拟合,包括权重w和偏置b
# prepare optimzier
# named_parameters()获取模型中的参数和参数名字
param_optimizer = list(model.named_parameters())
print(f'param_optimizer--->{param_optimizer}')
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"] # no_decay中存放不进行权重衰减的参数{因为bert官方代码对这三项免于正则化}
# any()函数用于判断给定的可迭代参数iterable是否全部为False,则返回False,如果有一个为True,则返回True
# 判断param_optimizer中所有的参数。如果不在no_decay中,则进行权重衰减;如果在no_decay中,则不进行权重衰减
optimizer_grouped_parameters = [
{"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], "weight_decay": 0.01},
{"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0}]
optimizer = AdamW(optimizer_grouped_parameters, lr=conf.learning_rate, eps=10e-8)
# 是否需要对bert进行warm_up。这里默认不进行
sheduler = None
return model, optimizer, sheduler, device
if __name__ == '__main__':
conf = Config()
# casrel = CasRel(conf)
# print(f'模型的架构--->{casrel}')
load_model(conf)
第二步: 编写工具类函数,训练函数,验证函数,测试函数¶
- 注意:工具类函数需要在训练、测试、评估过程中使用;训练函数, 验证函数两者在一个脚本,测试函数单独一个脚本. 此外, 因为验证函数和测试函数一致,因此只写一个即可.
- 第一步: 实现utils函数.
- 代码路径: /home/ec2-user/Casrel_RE/relationship_extract/codes/utils/process.py
# coding:utf-8
from codes.config import *
import torch
from random import choice
from collections import defaultdict
conf = Config()
def extract_sub(pred_sub_heads, pred_sub_tails):
'''
:param pred_sub_heads: 模型预测出的主实体开头位置
:param pred_sub_tails: 模型预测出的主实体尾部位置
:return: subs列表里面对应的所有实体【head, tail】
'''
subs = []
# 统计预测出所有值为1的元素索引位置
heads = torch.arange(0, len(pred_sub_heads), device=conf.device)[pred_sub_heads == 1]
tails = torch.arange(0, len(pred_sub_tails), device=conf.device)[pred_sub_tails == 1]
for head, tail in zip(heads, tails):
if tail >= head:
subs.append((head.item(), tail.item()))
return subs
def extract_obj_and_rel(obj_heads, obj_tails):
'''
:param obj_heads: 模型预测出的从实体开头位置以及关系类型
:param obj_tails: 模型预测出的从实体尾部位置以及关系类型
:return: obj_and_rels:元素形状:(rel_index, start_index, end_index)
'''
obj_heads = obj_heads.T
obj_tails = obj_tails.T
rel_count = obj_heads.shape[0]
obj_and_rels = []
for rel_index in range(rel_count):
obj_head = obj_heads[rel_index]
obj_tail = obj_tails[rel_index]
objs = extract_sub(obj_head, obj_tail)
if objs:
for obj in objs:
start_index, end_index = obj
obj_and_rels.append((rel_index, start_index, end_index))
return obj_and_rels
def convert_score_to_zero_one(tensor):
'''
以0.5为阈值,大于0.5的设置为1,小于0.5的设置为0
'''
tensor[tensor >= 0.5] = 1
tensor[tensor < 0.5] = 0
return tensor
- 导入实现训练函数,验证函数,测试函数的工具包
# coding:utf-8
from model.CasrelModel import *
from utils.process import *
from utils.data_loader import *
from config import *
import pandas as pd
from tqdm import tqdm
- 第二步: 编写训练与验证函数.
- 代码路径: /home/ec2-user/Casrel_RE/relationship_extract/codes/train.py
- 注意: 验证函数的目的是在训练过程中,保存F1值最好的模型状态,因此嵌套在训练过程中
def model2train(model, train_iter, dev_iter, optimizer, conf):
epochs = conf.epochs
best_triple_f1 = 0
for epoch in range(epochs):
train_epoch(model, train_iter, dev_iter, optimizer, best_triple_f1, epoch)
torch.save(model.state_dict(), '../save_model/last_model.pth')
def train_epoch(model, train_iter, dev_iter, optimizer, best_triple_f1, epoch):
for step, (inputs, labels) in enumerate(tqdm(train_iter)):
model.train()
logist = model(**inputs)
loss = model.compute_loss(**logist, **labels)
model.zero_grad()
loss.backward()
optimizer.step()
if step % 1500 == 0:
torch.save(model.state_dict(),
'../save_model/epoch_%s_model_%s.pth' % (epoch, step))
results = model2dev(model, dev_iter)
print(results[-1])
if results[-2] > best_triple_f1:
best_triple_f1 = results[-2]
torch.save(model.state_dict(), '../save_model/best_f1.pth')
print('epoch:{},'
'step:{},'
'sub_precision:{:.4f}, '
'sub_recall:{:.4f}, '
'sub_f1:{:.4f}, '
'triple_precision:{:.4f}, '
'triple_recall:{:.4f}, '
'triple_f1:{:.4f},'
'train loss:{:.4f}'.format(epoch,
step,
results[0],
results[1],
results[2],
results[3],
results[4],
results[5],
loss.item()))
return best_triple_f1
- 第三步: 编写验证函数.
- 代码路径: /home/ec2-user/Casrel_RE/relationship_extract/codes/train.py
def model2dev(model, dev_iter):
'''
验证模型效果
:param model:
:param dev_iter:
:return:
'''
model.eval()
# 定义一个df,来展示模型的指标。
df = pd.DataFrame(columns=['TP', 'PRED', "REAL", 'p', 'r', 'f1'], index=['sub', 'triple'])
df.fillna(0, inplace=True)
for inputs, labels in tqdm(dev_iter):
logist = model(**inputs)
pred_sub_heads = convert_score_to_zero_one(logist['pred_sub_heads'])
pred_sub_tails = convert_score_to_zero_one(logist['pred_sub_tails'])
sub_heads = convert_score_to_zero_one(labels['sub_heads'])
sub_tails = convert_score_to_zero_one(labels['sub_tails'])
batch_size = inputs['input_ids'].shape[0]
obj_heads = convert_score_to_zero_one(labels['obj_heads'])
obj_tails = convert_score_to_zero_one(labels['obj_tails'])
pred_obj_heads = convert_score_to_zero_one(logist['pred_obj_heads'])
pred_obj_tails = convert_score_to_zero_one(logist['pred_obj_tails'])
for batch_index in range(batch_size):
pred_subs = extract_sub(pred_sub_heads[batch_index].squeeze(),
pred_sub_tails[batch_index].squeeze())
true_subs = extract_sub(sub_heads[batch_index].squeeze(),
sub_tails[batch_index].squeeze())
pred_ojbs = extract_obj_and_rel(pred_obj_heads[batch_index],
pred_obj_tails[batch_index])
true_objs = extract_obj_and_rel(obj_heads[batch_index],
obj_tails[batch_index])
df['PRED']['sub'] += len(pred_subs)
df['REAL']['sub'] += len(true_subs)
for true_sub in true_subs:
if true_sub in pred_subs:
df['TP']['sub'] += 1
df['PRED']['triple'] += len(pred_ojbs)
df['REAL']['triple'] += len(true_objs)
for true_obj in true_objs:
if true_obj in pred_ojbs:
df['TP']['triple'] += 1
df.loc['sub', 'p'] = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
df.loc['sub', 'r'] = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
df.loc['sub', 'f1'] = 2 * df['p']['sub'] * df['r']['sub'] / (df['p']['sub'] +
df['r']['sub'] +
1e-9)
sub_precision = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
sub_recall = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
sub_f1 = 2 * sub_precision * sub_recall / (sub_precision + sub_recall + 1e-9)
df.loc['triple', 'p'] = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
df.loc['triple', 'r'] = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
df.loc['triple', 'f1'] = 2 * df['p']['triple'] * df['r']['triple'] / (
df['p']['triple'] + df['r']['triple'] + 1e-9)
triple_precision = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
triple_recall = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
triple_f1 = 2 * triple_precision * triple_recall / (
triple_precision + triple_recall + 1e-9)
return sub_precision, sub_recall, sub_f1, triple_precision, triple_recall, triple_f1, df
- 第四步: 编写测试函数.
- 代码路径:/home/ec2-user/Casrel_RE/relationship_extract/codes/test.py
def model2test(model, test_iter):
'''
测试模型效果
:param model:
:param test_iter:
:return:
'''
model.eval()
# 定义一个df,来展示模型的指标。
df = pd.DataFrame(columns=['TP', 'PRED', "REAL", 'p', 'r', 'f1'], index=['sub', 'triple'])
df.fillna(0, inplace=True)
with torch.no_grad():
for inputs, labels in tqdm(test_iter):
logist = model(**inputs)
pred_sub_heads = convert_score_to_zero_one(logist['pred_sub_heads'])
pred_sub_tails = convert_score_to_zero_one(logist['pred_sub_tails'])
sub_heads = convert_score_to_zero_one(labels['sub_heads'])
sub_tails = convert_score_to_zero_one(labels['sub_tails'])
batch_size = inputs['input_ids'].shape[0]
obj_heads = convert_score_to_zero_one(labels['obj_heads'])
obj_tails = convert_score_to_zero_one(labels['obj_tails'])
pred_obj_heads = convert_score_to_zero_one(logist['pred_obj_heads'])
pred_obj_tails = convert_score_to_zero_one(logist['pred_obj_tails'])
for batch_index in range(batch_size):
pred_subs = extract_sub(pred_sub_heads[batch_index].squeeze(),
pred_sub_tails[batch_index].squeeze())
true_subs = extract_sub(sub_heads[batch_index].squeeze(),
sub_tails[batch_index].squeeze())
pred_ojbs = extract_obj_and_rel(pred_obj_heads[batch_index],
pred_obj_tails[batch_index])
true_objs = extract_obj_and_rel(obj_heads[batch_index],
obj_tails[batch_index])
df['PRED']['sub'] += len(pred_subs)
df['REAL']['sub'] += len(true_subs)
for true_sub in true_subs:
if true_sub in pred_subs:
df['TP']['sub'] += 1
df['PRED']['triple'] += len(pred_ojbs)
df['REAL']['triple'] += len(true_objs)
for true_obj in true_objs:
if true_obj in pred_ojbs:
df['TP']['triple'] += 1
df.loc['sub', 'p'] = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
df.loc['sub', 'r'] = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
df.loc['sub', 'f1'] = 2 * df['p']['sub'] * df['r']['sub'] / (df['p']['sub'] + df['r']['sub'] + 1e-9)
df.loc['triple', 'p'] = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
df.loc['triple', 'r'] = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
df.loc['triple', 'f1'] = 2 * df['p']['triple'] * df['r']['triple'] / (
df['p']['triple'] + df['r']['triple'] + 1e-9)
return df
第三步: 编写模型预测函数¶
- 使用训练好的模型,随机抽取文本进行关系抽取
- 代码位置: /home/ec2-user/Casrel_RE/relationship_extract/codes/predict.py
# coding:utf-8
from model.CasrelModel import *
from utils.process import *
conf = Config()
def load_model(model_path):
# 实例化模型
mymodel = CasRel(conf).to(conf.device)
mymodel.load_state_dict(torch.load(model_path))
return mymodel
def get_inputs(sample, model):
text = conf.tokenizer(sample)
input_ids = torch.tensor([text['input_ids']]).to(conf.device)
mask = torch.tensor([text['attention_mask']]).to(conf.device)
# 初始化值
seq_len = len(text['input_ids'])
inner_sub_head2tail = torch.zeros(seq_len)
inner_sub_len = torch.tensor([1], dtype=torch.float)
# 获取模型预测的实体位置信息
model.eval()
with torch.no_grad():
# 先利用模型获取主实体的位置信息
encoded_text = model.get_encoded_text(input_ids, mask)
sub_heads, sub_tails = model.get_subs(encoded_text)
pred_sub_heads = convert_score_to_zero_one(sub_heads)
pred_sub_tails = convert_score_to_zero_one(sub_tails)
# 获取主实体索引位置信息
pred_subs = extract_sub(pred_sub_heads.squeeze(), pred_sub_tails.squeeze())
# 模型可能没识别出实体
if len(pred_subs) != 0:
sub_head_idx = pred_subs[0][0]
sub_tail_idx = pred_subs[0][1]
# 获取主体长度以及对主体位置全部赋值为1
inner_sub_head2tail[sub_head_idx:sub_tail_idx + 1] = 1
inner_sub_len = torch.tensor([sub_tail_idx + 1 - sub_head_idx], dtype=torch.float)
sub_len = inner_sub_len.unsqueeze(0).to(conf.device)
sub_head2tail = inner_sub_head2tail.unsqueeze(0).to(conf.device)
inputs = {'input_ids': input_ids,
'mask': mask,
'sub_head2tail': sub_head2tail,
'sub_len': sub_len}
return inputs, model
def model2predict(sample, model):
with open(conf.rel_dict_path, 'r', encoding='utf-8')as fr:
rel_id2word = json.load(fr)
inputs, model = get_inputs(sample, model)
logist = model(**inputs)
print(f"logist['pred_sub_heads']-->{logist['pred_sub_heads'].shape}")
print(f"logist['pred_obj_heads']-->{logist['pred_obj_heads'].shape}")
pred_sub_heads = convert_score_to_zero_one(logist['pred_sub_heads'])
pred_sub_tails = convert_score_to_zero_one(logist['pred_sub_tails'])
pred_obj_heads = convert_score_to_zero_one(logist['pred_obj_heads'])
pred_obj_tails = convert_score_to_zero_one(logist['pred_obj_tails'])
new_dict = {}
spo_list = []
ids = inputs['input_ids'][0]
text_list = conf.tokenizer.convert_ids_to_tokens(ids)
sentence = ''.join(text_list[1: -1])
pred_subs = extract_sub(pred_sub_heads[0].squeeze(), pred_sub_tails[0].squeeze())
pred_objs = extract_obj_and_rel(pred_obj_heads[0], pred_obj_tails[0])
if len(pred_subs) == 0 or len(pred_objs) == 0:
print('没有识别出结果')
return {}
if len(pred_objs) > len(pred_subs):
pred_subs = pred_subs * len(pred_objs)
for sub, rel_obj in zip(pred_subs, pred_objs):
sub_spo = {}
sub_head, sub_tail = sub
sub = ''.join(text_list[sub_head: sub_tail + 1])
if '[PAD]' in sub:
continue
sub_spo['subject'] = sub
relation = rel_id2word[str(rel_obj[0])]
obj_head, obj_tail = rel_obj[1], rel_obj[2]
obj = ''.join(text_list[obj_head: obj_tail + 1])
if '[PAD]' in obj:
continue
sub_spo['predicate'] = relation
sub_spo['object'] = obj
spo_list.append(sub_spo)
new_dict['text'] = sentence
new_dict['spo_list'] = spo_list
return new_dict
if __name__ == '__main__':
sample = "《人间》是王菲演唱歌曲"
model_path = '../save_model/last_model.pth'
mymodel = load_model(model_path)
model2predict(sample, mymodel)
- 调用:
cd /home/Desktop/relationship_extract/codes/
# 实现模型训练
python train.py
- 输出结果:
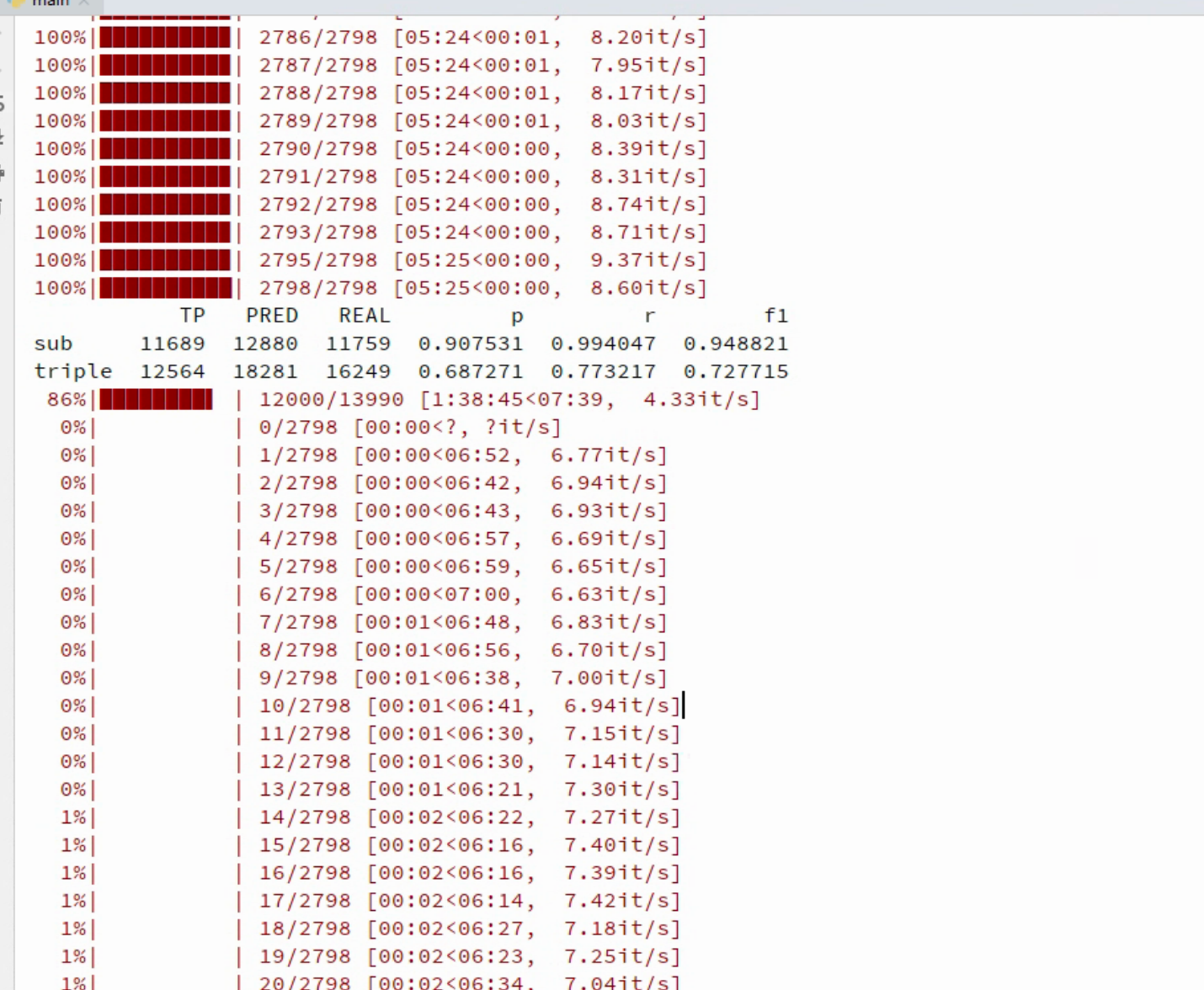
- 结论: Casrel模型在训练集上的表现是F1: 72.7%
7 Joint联合抽取方法的优缺点¶
- 优点:
- 两个任务的表征有交互作用可能辅助任务的学习.
- 不用训练多个模型,一个模型解决问题,减少训练与预测的gap.
- 缺点:
- 更复杂的模型结构.
- Joint方法提取的特征可能一致,也可能冲突会使模型学习变得混乱.
小节总结:¶
- 本章节主要介绍了什么是Joint联合抽取方法,并基于Casrel模型从0到1实现了关系抽取任务。